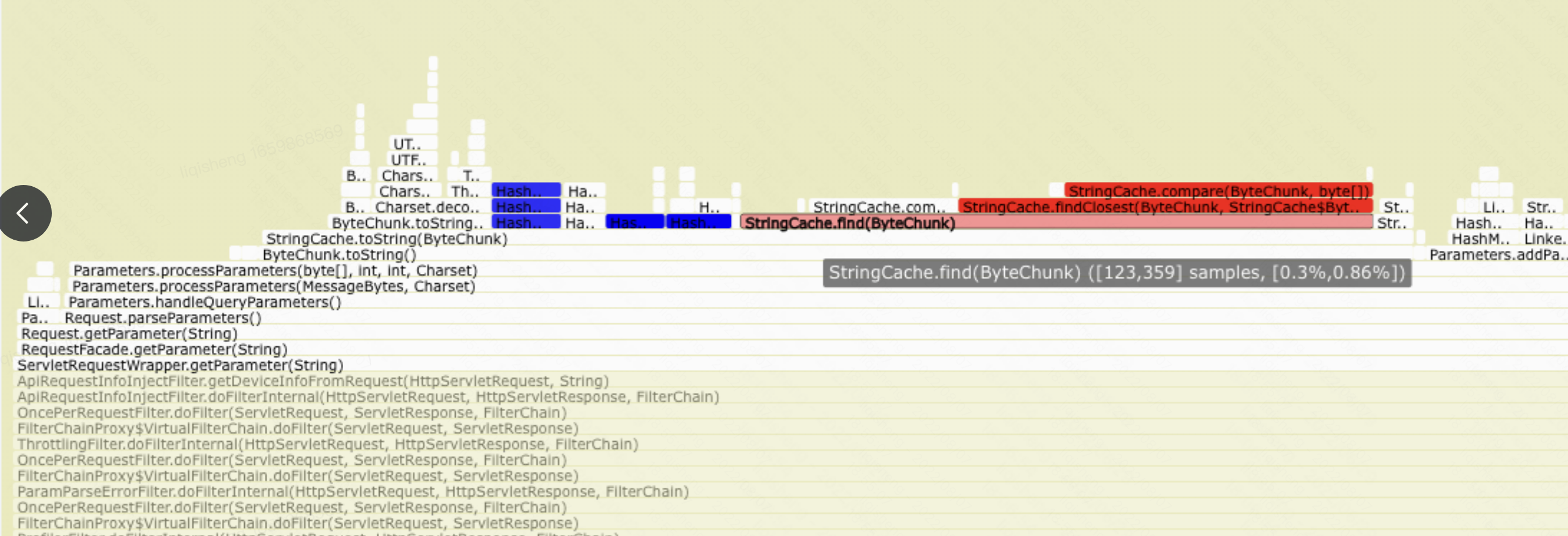
//org.apache.tomcat.util.buf.StringCache#findClosest(org.apache.tomcat.util.buf.ByteChunk, org.apache.tomcat.util.buf.StringCache.ByteEntry[], int) /** * Find an entry given its name in a sorted array of map elements. * This will return the index for the closest inferior or equal item in the * given array. * @param name The name to find * @param array The array in which to look * @param len The effective length of the array * @return the position of the best match */ protectedstaticfinalintfindClosest(ByteChunk name, ByteEntry[] array, int len){
// 二分查找的low和high int a = 0; int b = len - 1;
// Special cases: -1 and 0 if (b == -1) { return -1; }
if (compare(name, array[0].name) < 0) { return -1; } if (b == 0) { return0; } // 以上是特殊的case int i = 0; while (true) { // 取中间坐标,用位运算避免溢出风险 i = (b + a) >>> 1; // compare的结果, -1, 0, 1 int result = compare(name, array[i].name); // 在右侧,更新low if (result == 1) { a = i; } elseif (result == 0) { // 正好查找到 return i; } else { // 在左侧,缩减high b = i; } // 特殊情况 if ((b - a) == 1) { int result2 = compare(name, array[b].name); if (result2 < 0) { return a; } else { return b; } } }
// org.apache.tomcat.util.buf.StringCache#toString(org.apache.tomcat.util.buf.ByteChunk) // If the cache is null, then either caching is disabled, or we're // still training if (bcCache == null) { // bcCache为空,1.在training阶段,2. cache被禁用了 // 所以这里直接调用了对应的toString方法 String value = bc.toStringInternal(); // 缓存开关打开了,开始构建缓存的统计信息 // 这里有个String上线的限制,有相应的bug:https://bz.apache.org/bugzilla/show_bug.cgi?id=41057 if (byteEnabled && (value.length() < maxStringSize)) { // If training, everything is synced synchronized (bcStats) { // If the cache has been generated on a previous invocation // while waiting for the lock, just return the toString // value we just calculated // double checked lock, 在同步代码块中再次check if (bcCache != null) { return value; } // Two cases: either we just exceeded the train count, in // which case the cache must be created, or we just update // the count for the string // 超过训练阈值,构建cache逻辑 if (bcCount > trainThreshold) { long t1 = System.currentTimeMillis(); // Sort the entries according to occurrence // stats中每个item的出现次数 TreeMap<Integer,ArrayList<ByteEntry>> tempMap = new TreeMap<>(); for (Entry<ByteEntry,int[]> item : bcStats.entrySet()) { ByteEntry entry = item.getKey(); int[] countA = item.getValue(); Integer count = Integer.valueOf(countA[0]); // Add to the list for that count ArrayList<ByteEntry> list = tempMap.get(count); if (list == null) { // Create list list = new ArrayList<>(); tempMap.put(count, list); } list.add(entry); } // Allocate array of the right size // 不能超过缓存的上限 int size = bcStats.size(); if (size > cacheSize) { size = cacheSize; } ByteEntry[] tempbcCache = new ByteEntry[size]; // Fill it up using an alphabetical order // and a dumb insert sort ByteChunk tempChunk = new ByteChunk(); int n = 0; while (n < size) { // TreeMap,这里取lastKey就是出现次数最多的 Object key = tempMap.lastKey(); ArrayList<ByteEntry> list = tempMap.get(key); // 出现次数并列的情况 for (int i = 0; i < list.size() && n < size; i++) { ByteEntry entry = list.get(i); tempChunk.setBytes(entry.name, 0, entry.name.length); // 二分查找,找到插入位置 int insertPos = findClosest(tempChunk, tempbcCache, n); if (insertPos == n) { tempbcCache[n + 1] = entry; } else { System.arraycopy(tempbcCache, insertPos + 1, tempbcCache, insertPos + 2, n - insertPos - 1); tempbcCache[insertPos + 1] = entry; } n++; } // 删除掉已经处理的 tempMap.remove(key); } // while loop bcCount = 0; // 构建完成,清理掉stat数据 bcStats.clear(); bcCache = tempbcCache; if (log.isDebugEnabled()) { long t2 = System.currentTimeMillis(); log.debug("ByteCache generation time: " + (t2 - t1) + "ms"); } } else { // ----------------- 以下是收集训练数据的过程 ----------------- bcCount++; // Allocate new ByteEntry for the lookup ByteEntry entry = new ByteEntry(); entry.value = value; int[] count = bcStats.get(entry); if (count == null) { int end = bc.getEnd(); int start = bc.getStart(); // Create byte array and copy bytes entry.name = newbyte[bc.getLength()]; System.arraycopy(bc.getBuffer(), start, entry.name, 0, end - start); // Set encoding entry.charset = bc.getCharset(); // Initialize occurrence count to one count = newint[1]; count[0] = 1; // Set in the stats hash map bcStats.put(entry, count); } else { // 更新出现的次数 count[0] = count[0] + 1; } } } } return value; } else { // 走缓存的逻辑,这里忽略 }